k-Nearest Neighbors
Target is predicted by local interpolation of the targets associated of the nearest neighbors in the training set
주변의 이웃을 보고 자신의 범주를 결정하는 알고리즘
1. KNN이란?
지도학습의 Classification 알고리즘 중 하나로, 가장 가까운 k개 이웃의 정보로 새로운 데이터의 Label을 예측하는 방법론입니다. 아래 그림처럼 검은색 점의 범주 정보는 주변 이웃들을 가지고 추론해낼 수 있습니다. 만약 k가 1이라면 오렌지색, k가 3이라면 녹색으로 분류(classification)하는 것이지요. 만약 회귀(regression) 문제라면 이웃들 종속변수(y)의 평균이 예측값이 됩니다. 학습용 알고리즘이 아님 lazy model 이웃점을 interpolation(보간)하기 위해 거리를 가중치로 사용 가능하지만, 느리다는 단점 있다. 이웃점의 개수 와 Interpolation 가중치는 k-Nearest Neighbors의 주요 hyperparameter입니다.
2. 노트북 목차
Import - 사용 라이브러리
Input Parameters - 사용 파라미터
Prepare the DataSet - 학습할 테스트 데이터셋
Model Fitting - 모델피팅
Performance Measures - 성능측정
Post-hoc/Diagnostics - 비교진단
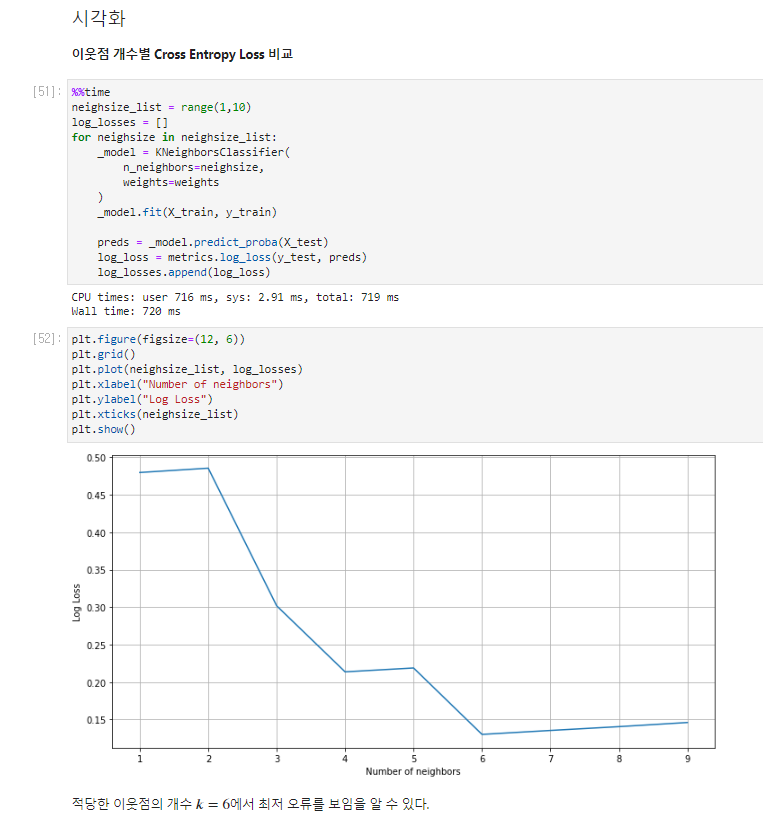
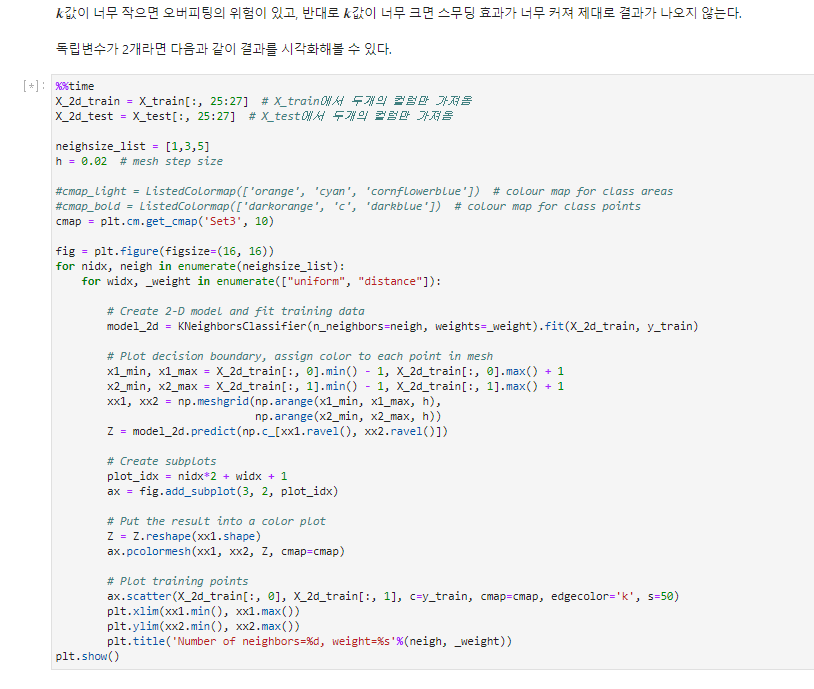
Visualization - 데이터 시각화
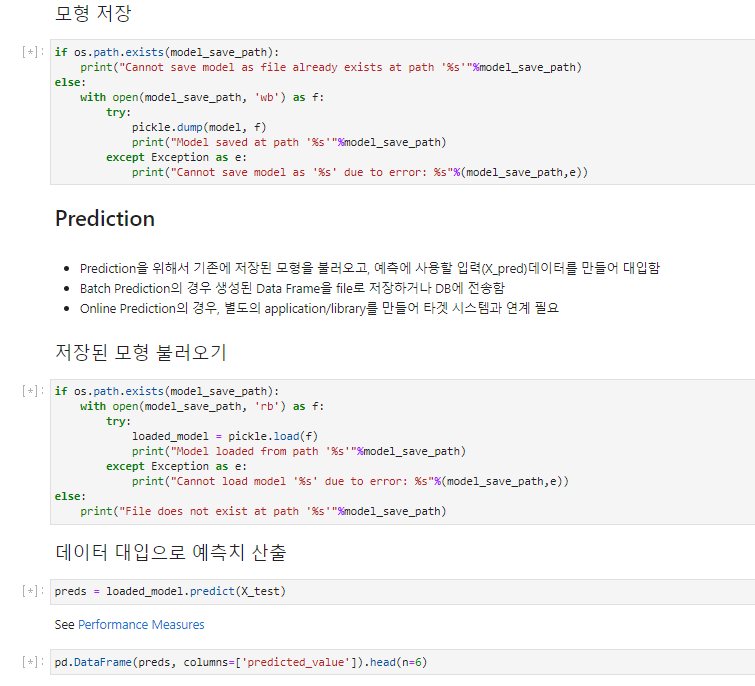
Save the model - 모형저장
Prediction - 예측
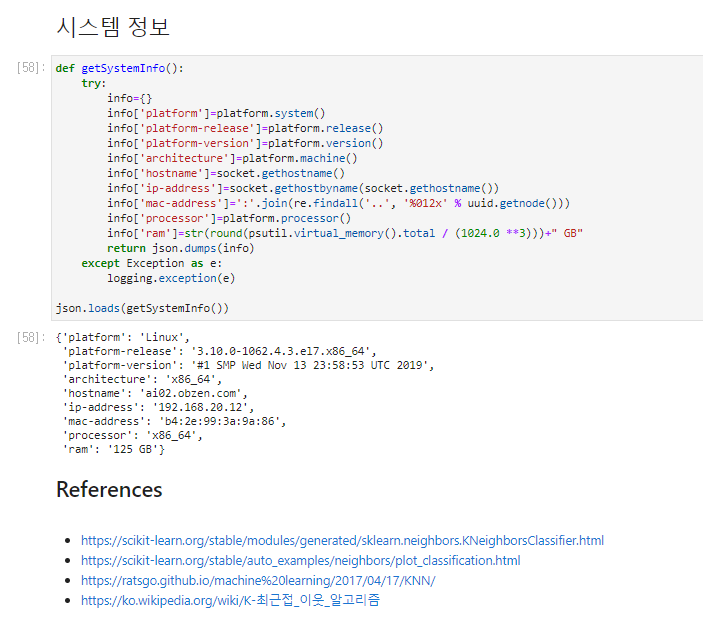
시스템 정보
3. Jupyter NoteBook
(1) Import

(2) Input Parameters

(3) Prepare the DataSet


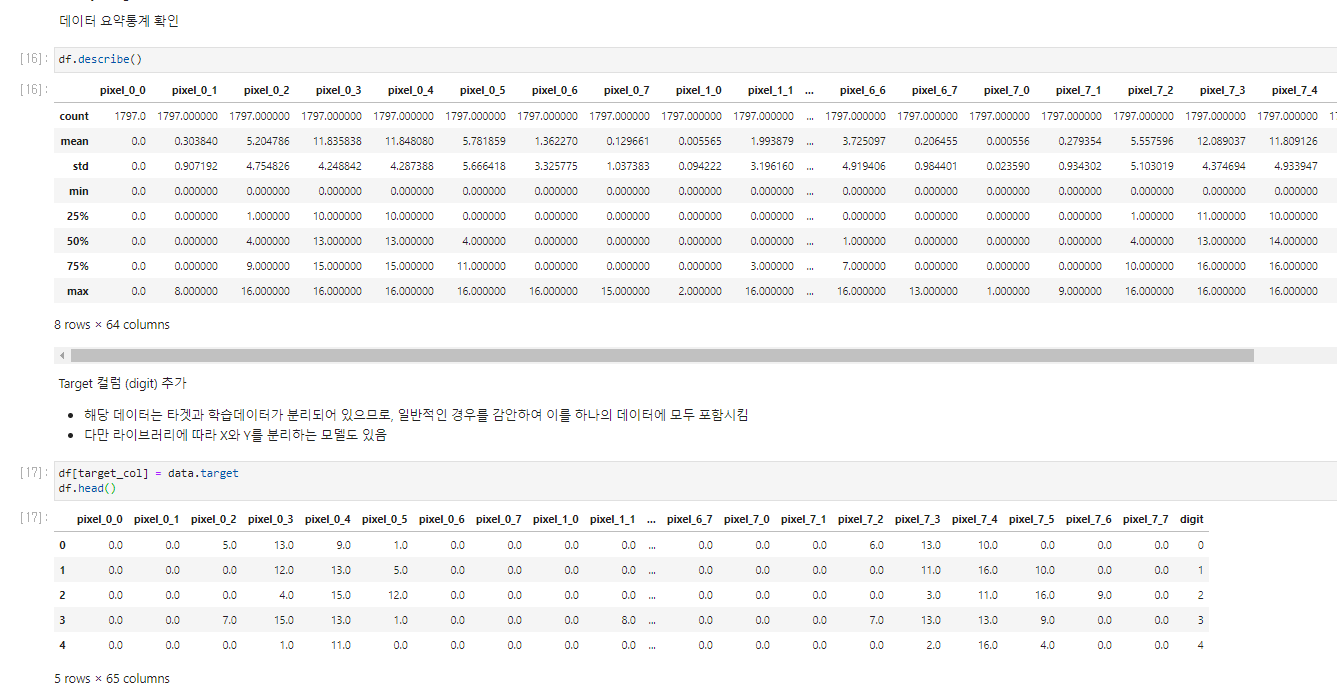
(4) Model Fitting
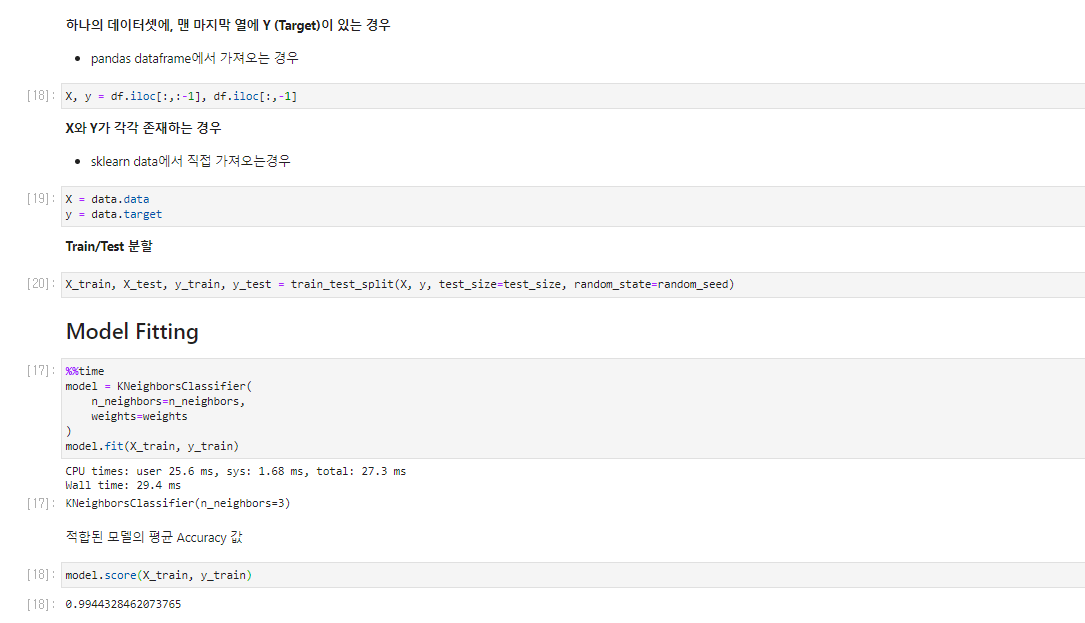
(5) Performance Measures
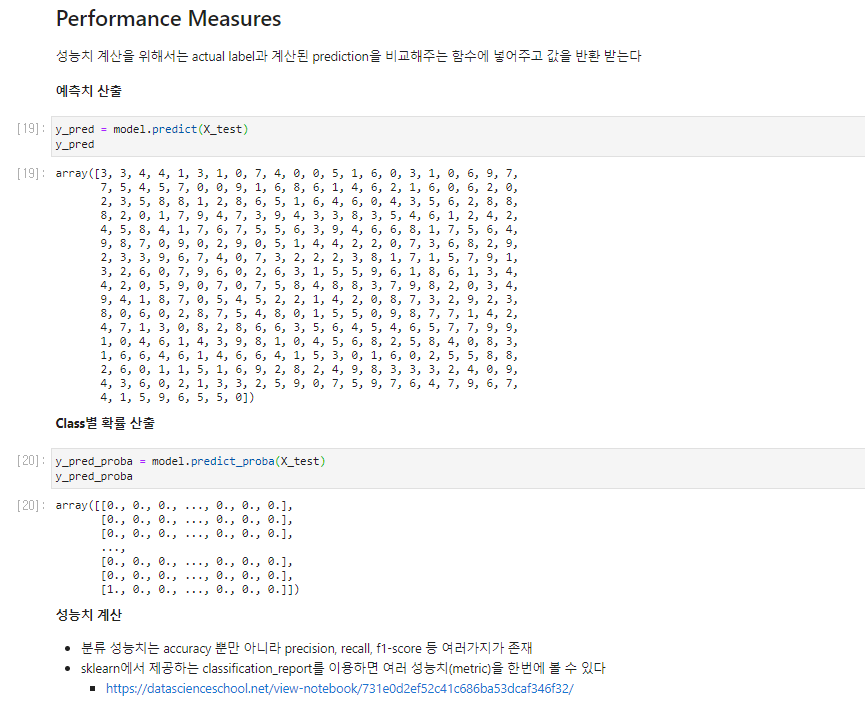
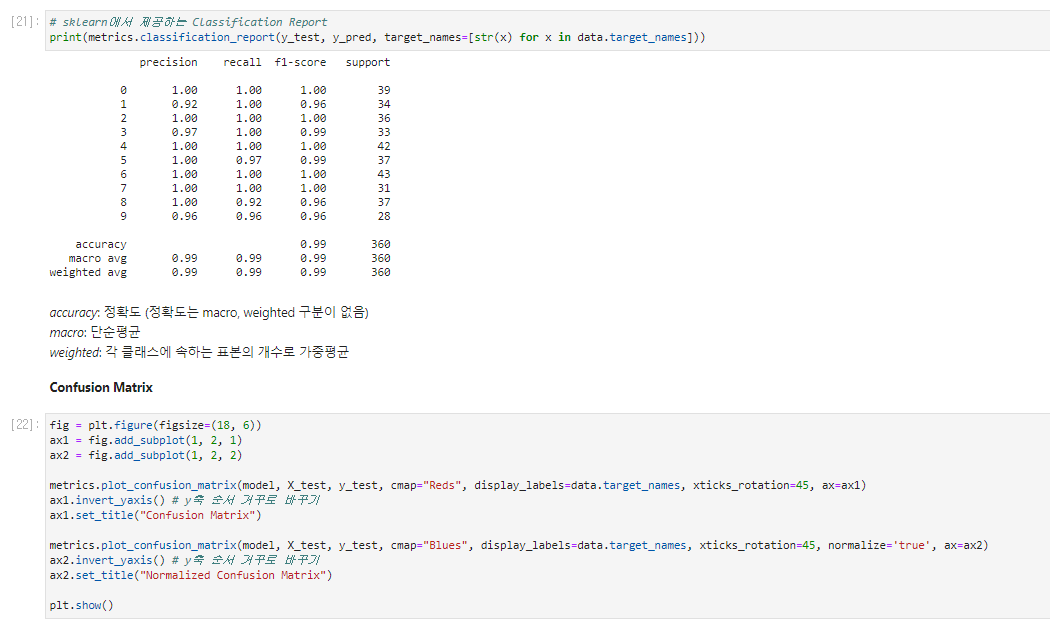
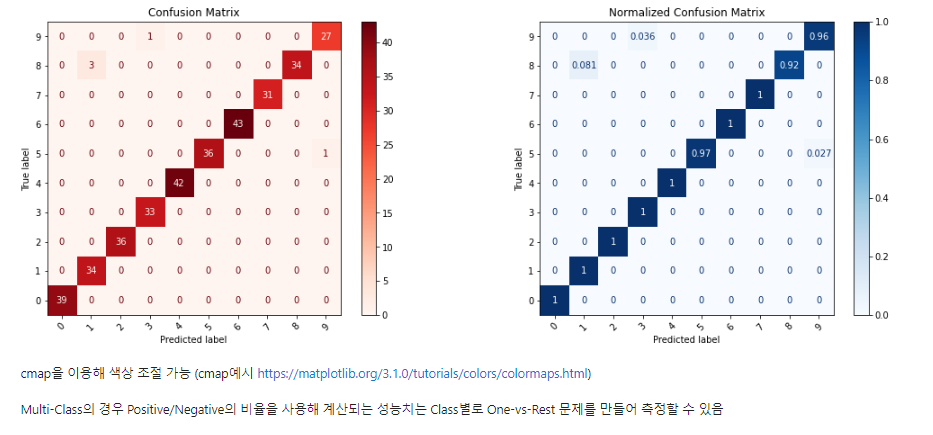
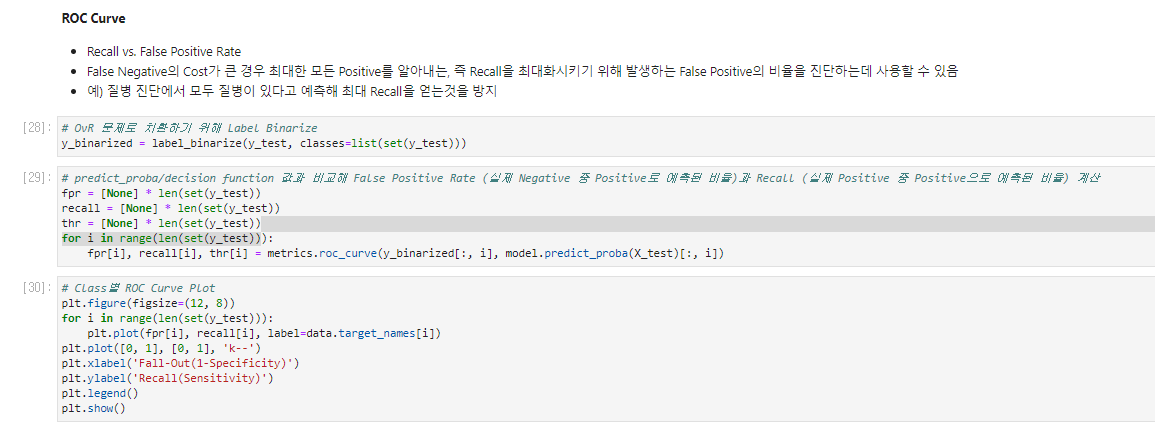
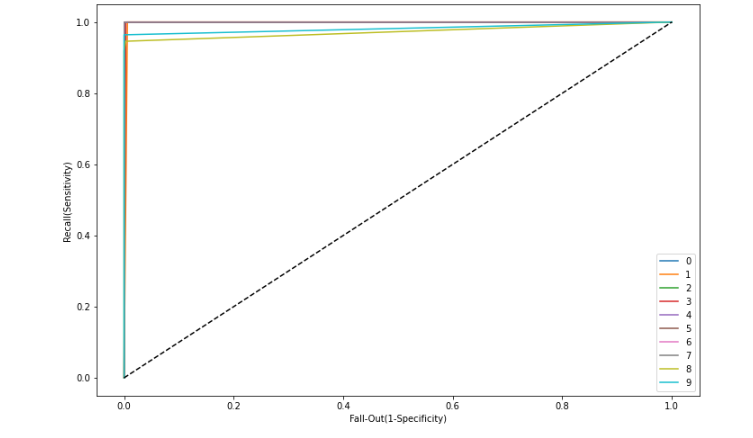
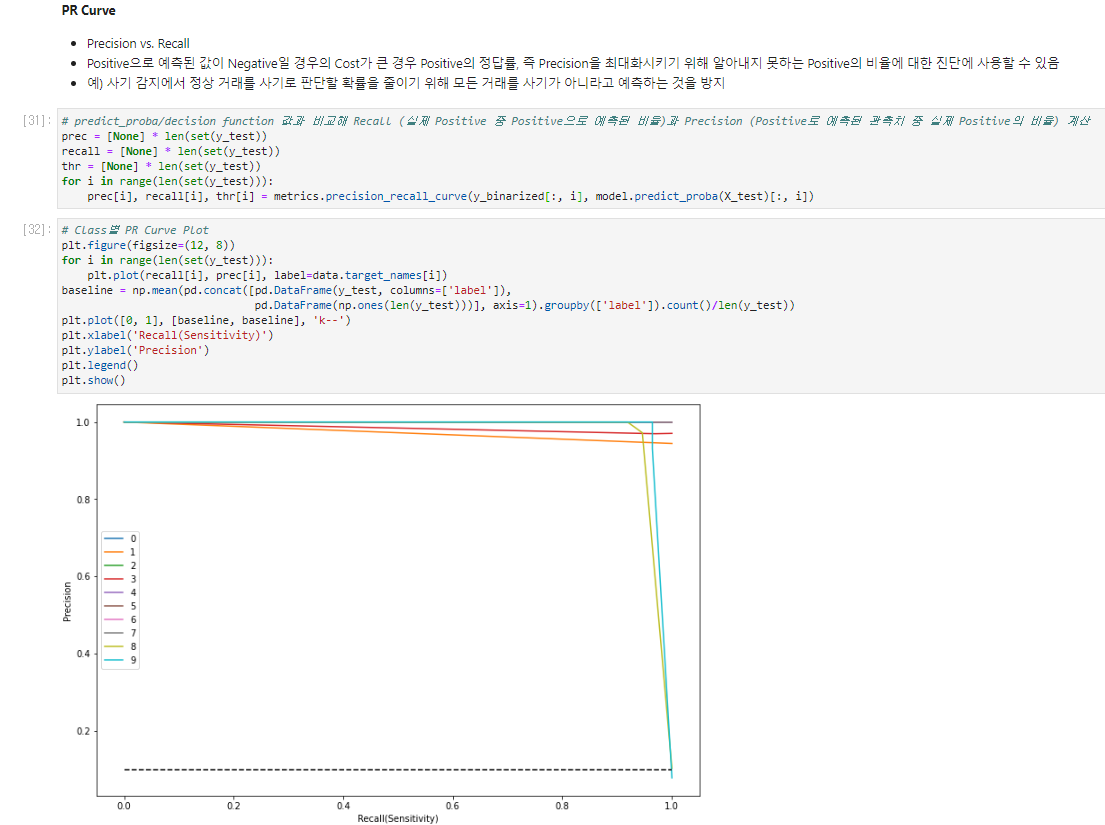
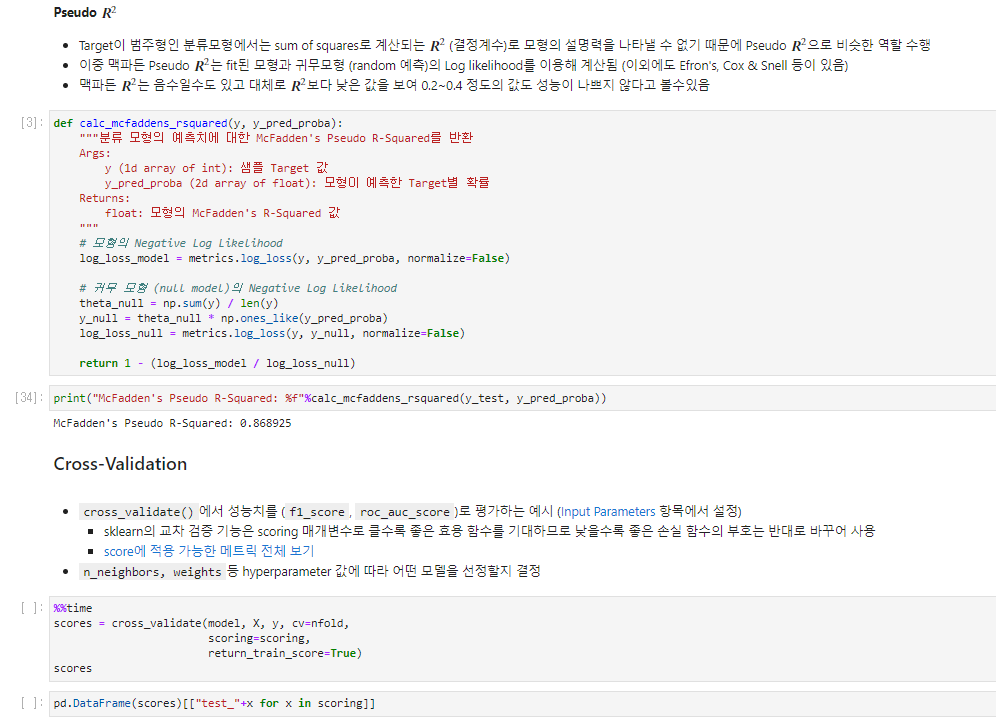
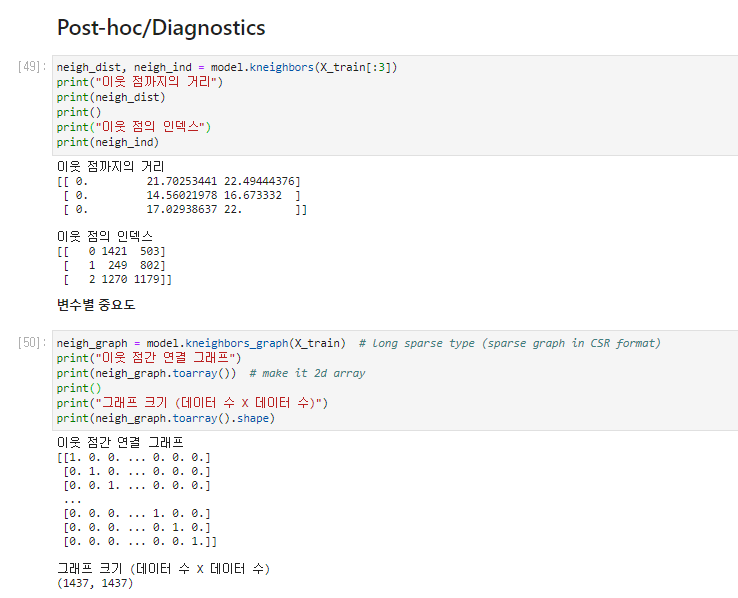
Post-hoc/Diagnostics - 비교진단
'Work > AI' 카테고리의 다른 글
| GPTs란? (0) | 2025.04.21 |
|---|---|
| ✅ AI 시대 - 가장 중요한 5가지 요소 (0) | 2025.04.21 |
| [AI] Regression (회귀) 개념, 분류 (0) | 2020.08.07 |
| [AI] Classification (분류) 개념과 알고리즘 종류 (2) | 2020.08.07 |
| [AI] Clustering (군집화) 개념과 알고리즘 종류 (0) | 2020.08.07 |



