https://www.acmicpc.net/step/9
정렬 단계
시간 복잡도가 O(nlogn)인 정렬 알고리즘으로 풀 수 있습니다. 예를 들면 병합 정렬, 힙 정렬 등이 있지만, 어려운 알고리즘이므로 지금은 언어에 내장된 정렬 함수를 쓰는 것을 추천드립니다.
www.acmicpc.net
백준문제는 생각보다 메모리와 시간제한이 빡빡한 편이다.
입력은 Scanner보다는 BufferdReader를
출력은 단순 for문 출력보다 StringBuilder로 받아 출력하는걸 기본으로 작성해야 한다.
정렬은 Arrays.sort O(n)~O(n2)보다 Collections.Sort O(nlogn)가 빠른 속도를 보장하지만,
Collections의 List, Set, Map를 사용하기 위해서는 Input의 범위와 메모리 제한을 고려해서 사용해야한다.
단순 배열보다 Collections Clasas가 더 많은 메모리를 먹기 때문이다.
✅ 2750 수 정렬하기
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 22,288kb 336ms - Scanner
// 14,456kb 132ms - BufferedReader
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
StringBuilder sb = new StringBuilder();
int[] arr = new int[n];
for(int i=0;i<n;i++)
arr[i] = Integer.parseInt(br.readLine());
br.close();
// 정렬
Arrays.sort(arr);
// 출력
for (int i : arr)
sb.append(i).append("\n");
System.out.println(sb.toString());
}
}
입력부분을 Scanner로 푼것과 아주 많은 성능 차이를 보인다.
1번 문제는 시간과 메모리제한이 크지 않았기에 Scanner도 사용이 가능했지만,
앞으로의 문제에서 시간과 메모리 제약이 더 커지기 때문에 입력을 받을때 BufferdReader를 사용하자
✅ 2751 수 정렬하기 2
이 문제는 첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000)이 주어지며 수가 중복되지 않는다고 말하고 있다.
중복되지 않는다는 특징은 Set을 떠올릴 수 있다. 즉 Arrays.sort보다 빠른 Collections.sort 를 이용할 수 있다.
Set은 HashSet이 아닌 TreeSet을 이용해 삽입과 동시에 정렬이 되도록 해주었다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.TreeSet;
public class Main {
// 259,840kb 2576ms - Array
// 220,344kb 1668ms - list
// 148,204kb 1816ms - TreeSet
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
TreeSet<Integer> set = new TreeSet<>();
for(int i=0;i<n;i++)
set.add(Integer.parseInt(br.readLine()));
br.close();
// 출력
StringBuilder sb = new StringBuilder();
for (int i : set){ sb.append(i).append("\n");}
System.out.println(sb.toString());
}
}3가지 방법으로 풀어 보았는데,
그 중 Arrays < List < TreeSet 순서로 빠르게 나왔다.
✅ 10989 수 정렬하기 3
해당 문제는 메모리와 시간제한이 조금 더 빡빡해서, Collections를 이용할 수 없었다. (OOM 발생)
대신 Arrays와 Counting 정렬 두가지 방법을 소개한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 359,676 kb 2456ms - Arrays
public class Main{
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int arr[] = new int[n];
for (int i = 0; i < n; i++)
arr[i] = Integer.parseInt(br.readLine());
br.close();
// 정렬
Arrays.sort(arr);
// 출력
StringBuilder sb = new StringBuilder();
for (int i : arr) {
sb.append(i).append("\n");
}
System.out.println(sb.toString());
}
}import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
// 336,404kb 1632ms - 카운팅 정렬
public static void main(String[] args) throws IOException {
// 입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int cnt[] = new int[10001]; // 1~10000까지의 자연수를 받을 공간
for(int i=0;i<n;i++)
cnt[Integer.parseInt(br.readLine())]++; // 해당수를 ++
br.close();
// 출력
StringBuilder sb = new StringBuilder();
for(int i=1;i<10001;i++){
while(cnt[i]>0){
sb.append(i).append("\n");
cnt[i]--;
}
}
System.out.println(sb.toString());
}
}두 방법이 메모리 사용량은 비슷하지만, 카운팅 정렬이 시간은 훨씬 빨랐다.
입력값의 범위가 작을수록 카운팅 정렬이 유리하다고 볼 수 있다.
✅ 2108 통계학 ★★★
- 산술평균 : N개의 수들의 합을 N으로 나눈 값
- 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
- 최빈값 : N개의 수들 중 가장 많이 나타나는 값
- 범위 : N개의 수들 중 최댓값과 최솟값의 차이
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main {
//68,384KB 760ms
public static void main(String[] args) throws IOException {
// 입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
HashMap<Integer,Integer> map = new HashMap<>();
int arr[] = new int[n];
int sum=0,mode;
for(int i=0;i<n;i++) {
arr[i] = Integer.parseInt(br.readLine());
sum+=arr[i]; // 1.합계 - 산술평균
map.put(arr[i],map.getOrDefault(arr[i],0)+1); // 3.최빈값
}
br.close();
// 계산
Arrays.sort(arr);
int mid = arr[arr.length/2]; //2. 중앙값 (N이 홀수이므로 신경쓰지 않아도 됨)
int range = arr[arr.length-1] - arr[0]; // 4.범위
List<Map.Entry<Integer,Integer>> list_entry = new ArrayList<Map.Entry<Integer,Integer>>(map.entrySet());
Collections.sort(list_entry, ((o1, o2) -> { // 최빈값 정렬
if(o2.getValue() == o1.getValue())
return o1.getKey() - o2.getKey(); // 빈도가 같으면, 오름차순 정렬
else
return o2.getValue() - o1.getValue(); // 빈도가 다르면, 빈도순 내림차순 정렬
}));
if(list_entry.size()>1 && list_entry.get(0).getValue() == list_entry.get(1).getValue()) // 최빈값이 순위가 같으면
mode = list_entry.get(1).getKey(); // 최빈값중 두번째로 작은값 출력
else
mode = list_entry.get(0).getKey();
// 출력
System.out.println(Math.round((float)sum/n)); // 1.산술평균
System.out.println(mid); // 2.중앙값
System.out.println(mode); // 3.최빈값
System.out.println(range); // 4.범위
}
}통계학 문제에서 평균(합계 / n), 중앙값(홀수이므로 길이/2 번째 원소), 범위 (마지막원소 - 0번째원소)는
정렬된 상태에서 어렵지 않게 나오지만, 최빈값은 다르다.
배열이나 Map같은 자료구조에 원소들이 몇번씩 나왔는지 기록해주고
최빈값이 높은 순서로 정렬하여 주어야한다. 그 중 최빈값이 같은 경우, 두번쨰로 작은 원소를 반환해야 하므로 까다롭다.
필자는 HashMap에 entrySet을 List로 가져와서 Comparator를 람다식으로 사용자 정렬해주어 풀었다.
✅ 1427 소트인사이드
입력이 하나이므로 Scanner를 사용해도 무방하다.
한자리 숫자이므로 문자로 취급하고 정렬해도 괜찮다.
import java.util.Arrays;
import java.util.Scanner;
// 17,688kb 220ms
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String n = sc.nextLine();
sc.close();
char[] arr = n.toCharArray();
Arrays.sort(arr);
StringBuilder sb = new StringBuilder();
for (int i=arr.length-1 ;i>=0;i--) {
sb.append(arr[i]);
}
System.out.println(sb.toString());
}
}내림차순으로 받기위해 for을 뒤에서부터 돌렸다.
✅ 11650 좌표 정렬하기
좌표값과 같이 2개의 속성을 가지는 데이터를 정렬하는 두가지 방법이있다.
1. N 배열의 사용 - 정렬의 Comparator사용을 해야한다.
2. 신규 Class 사용 - Comparable 인터페이스를 재정의하는 방법으로도 풀 수 있다.
나는 편의를 위해 방금전 소트인사이드 문제와 같이 2차원 배열을 이용해보겠다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 79,720 kb , 824ms
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[][] arr = new int[n][2];
for (int i = 0; i < n; i++){
String tmp = br.readLine();
arr[i][0] = Integer.parseInt(tmp.split(" ")[0]);
arr[i][1] = Integer.parseInt(tmp.split(" ")[1]);
}
br.close();
// 정렬
Arrays.sort(arr, (o1, o2) -> {
if(o1[0] == o2[0])
return o1[1] - o2[1];
else
return o1[0] - o2[0];
});
// 출력
StringBuilder sb = new StringBuilder();
for (int[] a: arr)
sb.append(a[0]).append(" ").append(a[1]).append("\n");
System.out.println(sb.toString());
}
}
✅ 11651 좌표 정렬하기 2
위와 동일한 문제로, 기준만 변경해주면 된다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 78,272 kb , 780ms
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[][] arr = new int[n][2];
for (int i = 0; i < n; i++){
String tmp = br.readLine();
arr[i][0] = Integer.parseInt(tmp.split(" ")[0]);
arr[i][1] = Integer.parseInt(tmp.split(" ")[1]);
}
br.close();
// 정렬
Arrays.sort(arr, (o1, o2) -> {
if(o1[1] == o2[1]) // 기준이 변경됨
return o1[0] - o2[0];
else
return o1[1] - o2[1];
});
// 출력
StringBuilder sb = new StringBuilder();
for (int[] a: arr)
sb.append(a[0]).append(" ").append(a[1]).append("\n");
System.out.println(sb.toString());
}
}
✅ 1181 단어 정렬
중복을 제거하고 출력하는건,
정렬된상태에서 앞에 문자열과 같은지를 검사하면서 넘어갈 수 도 있고
애초에 Set자료구조를 이용할 수도 있다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 26,824kb ,336 ms
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
String[] arr = new String[n];
for (int i = 0; i < n; i++){
arr[i] = br.readLine();
}
br.close();
// 정렬
Arrays.sort(arr, (o1, o2) -> {
if(o1.length() == o2.length())
return o1.compareTo(o2);
else
return o1.length() - o2.length();
});
// 출력
StringBuilder sb = new StringBuilder();
String tmp ="";
for (String s: arr) {
if(!tmp.equals(s)) // 중복검사
sb.append(s).append("\n");
tmp = s;
}
System.out.println(sb.toString());
}
}
✅ 10814 나이순 정렬
나이순서로 정렬하되, 나이가 같으면 가입 순서(Input순서)로 정렬해야 한다.
나이와 이름은 다른 자료형을 가지기 때문에, 2차원 배열에 넣을 수 없다.
즉, 클래스를 만들어서 풀던가, TreeMap을 이용해서 풀어야 한다.
정석적으로 클래스를 생성하고, Comparable을 사용해보겠다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 73,884kb ,740 ms
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
Person[] arr = new Person[n];
for (int i = 0; i < n; i++){
String tmp = br.readLine();
arr[i] = new Person(Integer.parseInt(tmp.split(" ")[0]), tmp.split(" ")[1]);
}
br.close();
// 정렬
Arrays.sort(arr);
// 출력
StringBuilder sb = new StringBuilder();
for (Person s: arr) {
sb.append(s.age).append(" ").append(s.name).append("\n");
}
System.out.println(sb.toString());
}
}
class Person implements Comparable<Person>{
int age;
String name;
public Person(int age,String name) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
return age - o.age;
}
}클래스에 Comparable을 상속하여 구현하게 되면,
해당 클래스 형식의 배열을 정렬하는 Arrays.sort에서 compareTo을 이용해 정렬하게 된다.
기본형 타입의 클래스는 모두 compareTo가 정의되어 있기 때문에, Arrays.sort가 가능한 것이다.
✅ 18870 좌표 압축 ★★★
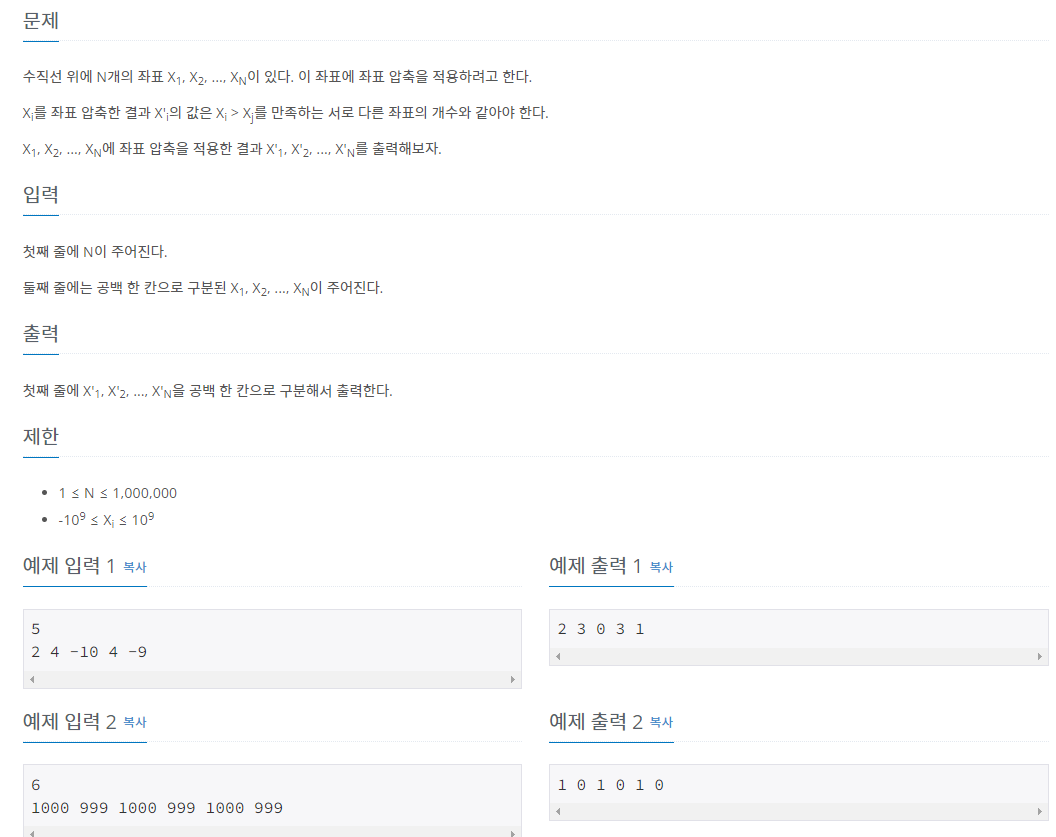
문제가 난해하다.
풀이의 시작은 문제이해인데, 출력을 한참보고나서 이해했다.
입력값에 따른 랭킹 리스트를 만드는 문제이다. (좌표값이랑 압축이랑은 아무런 관계가 없음)
(문제 이름좀 바꿨으면..;;)
다차원배열에 들어온 순서를 id값으로 넣고 (복기를 위함),
좌표값을 오름차순으로 정렬 해준 후
랭킹을 기록하고 다시 id값 순서로 재정렬시켜 랭킹을 출력하면 된다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 219,776 kb , 3724ms
public class Main {
public static void main(String[] args) throws IOException {
//입력
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
String [] tmp = br.readLine().split(" ");
int[][] arr = new int[n][3]; // 0 : index , 1 : 좌표값 , 2 : rank 기록
for (int i = 0; i < n; i++){
arr[i][0] = i;
arr[i][1] = Integer.parseInt(tmp[i]);
}
br.close();
// 좌표값 정렬
Arrays.sort(arr, (o1, o2) -> o1[1] - o2[1]);
// 순위 기록
int rank=0,next=arr[0][1];
for (int i=0;i<arr.length;i++) {
if(next!=arr[i][1])
rank++;
arr[i][2] = rank;
next = arr[i][1];
}
// input 순서로 재정렬
Arrays.sort(arr,(o1,o2)->o1[0]-o2[0]);
// 출력
StringBuilder sb = new StringBuilder();
for (int[] a: arr)
sb.append(a[2]).append(" ");
System.out.println(sb.toString());
}
}
통계학과 좌표압축에 조금 난이도가 있었던 것 같다.
대부분 쉬웠는데, 오름차순 정렬보다는 역순정렬로 문제가 나왔으면 더 학습하기 좋았을것 같다.
정렬문제는 프로그래머스가 학습하기에 난이도가 좀 더 높은것 같다.
'Algorithm > 백준 단계별 문제' 카테고리의 다른 글
| [백준] 14. 동적계획법1 - Java코드😨 (0) | 2022.04.21 |
|---|---|
| [백준] 13. 백트래킹 - Java 코드 (0) | 2022.04.15 |
| [백준] 11. Brute Force - Java 코드 (0) | 2022.02.17 |
| [백준] 7. String 문자열 - Java 코드 (0) | 2020.01.27 |
| [백준] 6. Funtion 함수 - Java 코드 (0) | 2020.01.27 |



