Key와 Value가 쌍을 이루는 자료구조로
사용할 데이터가 쌍을 이루는 경우,
필요한 데이터를 키 값을 통해, 아주 빠르게 탐색가능하며,
키가 고유의 해쉬함수를 통해 데이터에 접근하는 구조로 이루어져 있다.
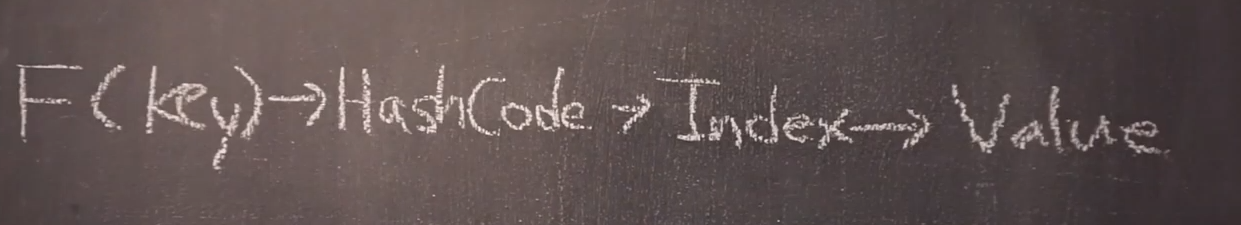
일반적으로 해시는 Key값을 Hash Function을 통해, HashCode를 내밷고,
저장공간의 Size로 나눠 Index를 정하여 Value값을 저장한다.
이 과정에서 다른 Key값에 대해서 Hash Function이 같은 HashCode를 내밷어서
같은 Index에 연결되어 저장되기도하고,
다른 Key값에 대해서 Hash Function이 다른 HashCode를 내밷어도,
Index를 구하는 과정에서 똑같은 공간을 가리켜 연결 저장되는 경우도있다.
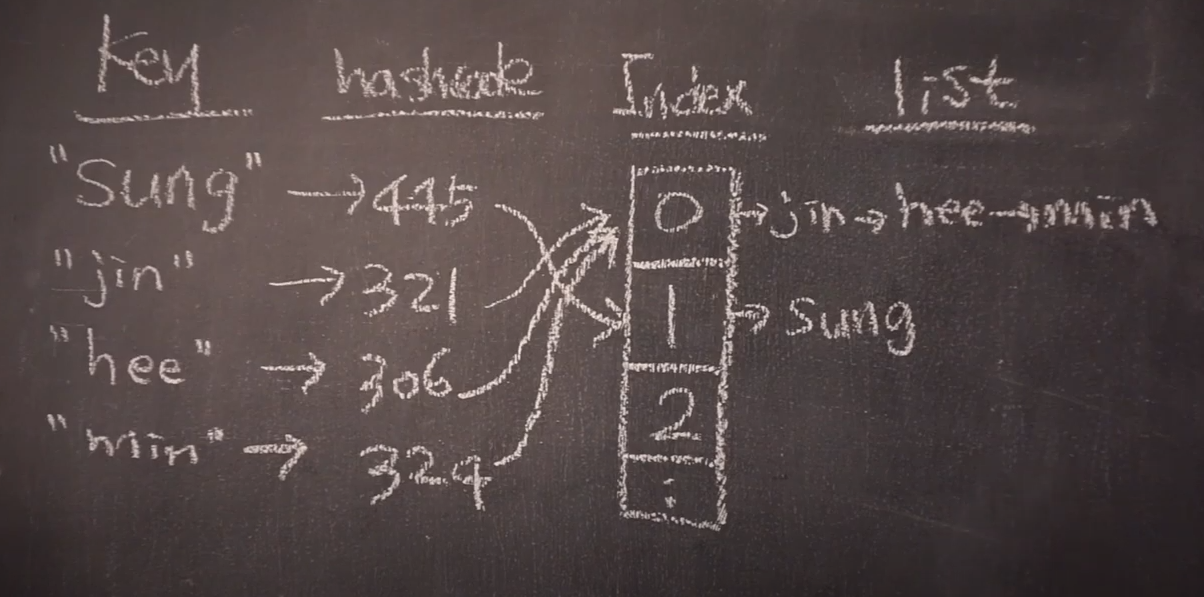
이렇게 다른 Key값에 대해서 Index가 충돌하는 경우를 Hash Collison (해시충돌)이라고 말한다.
해시충돌은 같은 공간에서 연결리스트로 저장되어 데이터를 가져오는게 문제가 되진 않지만,
해시에 가장 큰 장점이 배열을 순차 탐색을 하지 않고,
Input Key값을 통해 바로 몇번째 Index에 저장 되어있는지 접근이 가능하다는 강점을 무너뜨리는 원인이 된다.
시간복잡도가 해시함수에 따라서 최악의 경우 , O(n)의 시간복잡도를 가질 수 있다.
그러니, 해시코드값을 최대한 겹치지않게 만들어주는 해시함수가 좋은 함수이다.
대표적인 해쉬함수로는 Division Method, Digit Folding, Multiplication Method, Univeral Hashing 등이 있다.
Java로 구현하는 Hash
import java.util.LinkedList;
public class hashTable {
class Node{
String key;
String value;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
String value() {
return value;
}
void value(String value) {
this.value = value;
}
}
// Node형 연결리스트로 선언
LinkedList<Node>[] data;
// 자신을 호출하면서 크기를 지정하여 선언
public hashTable(int size) {
this.data = new LinkedList[size];
}
// Key값을 통해 HashCode 생성 - 아스키코드이용
int gethashCode(String key) {
int hashcode=0;
for(char c : key.toCharArray())
hashcode+=c;
return hashcode;
}
// HashCode를 이용해서 Index를 지정
int convertToIndex(int hashcode) {
return hashcode%data.length;
}
Node searchKey(LinkedList<Node> list, String key) {
if(list == null ) return null;
for(Node node : list) {
if(node.key.equals(key)) {
return node;
}
}
return null;
}
// Key를 통한 값 저장
void set(String key,String value) {
int index = convertToIndex(gethashCode(key));
LinkedList<Node> list = data[index];
// 없으면 저장
if(list == null) {
list = new LinkedList<Node>();
data[index] = list;
}
Node node = searchKey(list, key);
if(node==null)
list.addLast(new Node(key,value));
else
node.value(value);
System.out.println("hashcode : "+gethashCode(key)+", index : " +index + ", ");
}
// key를 통한 값 호출
String get(String key) {
int index = convertToIndex(gethashCode(key));
LinkedList<Node> list = data[index];
if(list == null)
return "Not Found";
else {
for(Node n : list) {
if(n.key.equals(key))
return n.value;
}
return null;
}
}
}
1. 클래스 정의
Key, Value를 가지는 Node라는 클래스를 정의하고, 초기화 함수와 Value를 삽입/조회 하는 함수를 만들어주었다.
연결리스트로 Node를 타입으로 가지도록 정의하고,
선언시 인자로 Size를 받아 크기를 초기화 하도록 해준다.
2. Hash함수 정의
gethashCode라는 이름으로 String형 Key가 들어오면 각 문자의 ASCII코드값을 더해줘 Code를 만들어 반환해주었다
3. Index변환
HashCode값을 배열의 크기로 나누어 인덱스값을 만들었다.
4. Key확인
Hash자료형에서 키는 중복되지않는 유일성을 가지는 자료형이므로,
존재여부를 확인이 저장시마다 필요하다.
5 get, put , remove 삽입 / 조회 / 삭제
삭제를 제외하고 기본적으로 get, put을 만들어주었다.
메인 클래스에서 사용
// 자바에서 HashTable을 더이상 지원하지않으므로, HashMap을 사용
import java.util.HashMap;
public class HashMapExam {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
map.put("bang", "cool");
map.put("byunggwok", "nice");
map.put("minjung", "pretty");
map.put("jiyeon", "sexy");
System.out.println(map.get("bang"));
System.out.println(map.get("byunggwok"));
System.out.println(map.get("minjung"));
System.out.println(map.get("jiyeon"));
}
}
Console Output

참조글
https://mangkyu.tistory.com/102
[자료구조] 해시테이블(HashTable)이란?
1. 해시테이블(HashTable)이란? [ HashTable(해시테이블)이란? ] 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른
mangkyu.tistory.com
https://withwani.tistory.com/150
JAVA Collection과 Map에 대해서
포스트 내용의 참고자료 출처 : 소설같은자바 Third Edition JAVA에서 기본적인 자료 구조를 제공하기 위한 환경을 JAVA Collection Framework라고 한다. 다음은 JAVA Collection Framework의 상속 기본 구조이..
withwani.tistory.com
https://ecsimsw.tistory.com/entry/Hash-Table-%EC%9B%90%EB%A6%AC%EC%99%80-%EA%B5%AC%ED%98%84
자바 깊이 알기 / Hash Table 원리와 구현
Hashing / HashTable key 값을 조작해서, 배열의 인덱스와 매핑한다면, key에 해당하는 value 값을 배열의 인덱스에 접근하는 것처럼, O(1)의 비용으로 가져올 수 있을 것이다. 예를들어, 과일 과게에서 과
ecsimsw.tistory.com
https://swexpertacademy.com/main/help/clause/learningGuide.do#none
https://www.youtube.com/watch?v=Vi0hauJemxA
'Algorithm > 알고리즘 정리' 카테고리의 다른 글
| [Combination]- Java코드 (DFS, BFS 방식 -성능비교) (0) | 2021.12.20 |
|---|---|
| 정렬 알고리즘 (2) - 퀵, 머지, 힙, JAVA 구현코드 (0) | 2021.07.08 |
| 정렬 알고리즘(1) - 버블, 선택, 삽입 , JAVA 구현코드 (2) | 2021.07.07 |
| [알고리즘] 알고리즘별, 자료구조별, 시간복잡도 - 총정리 (0) | 2021.07.02 |



